

Data on Entertainment
Even though Hollywood may seem so glittery from the outside, on the inside it’s an industry like any other. And the currency of modern business is often represented by data.
With this post I’ve tried to sum up all of the main sources of publicly accessible data on entertainment. I’ve privileged sources that are also open: whereas you can use the data for your purposes under a certain license.
Why so few open data sources?
Of the data that allows the movie and TV industries to function, very little is open. In the table below I’ve selected all the sources that feature more than 1.000 items. Some even have a proper open data license. Most of them don’t.
If you see any source missing please let me know in the comments below and I will add it.
Open Data Entertainment Sources
| Name | Description | Format | License | Notes | Last Update |
|---|---|---|---|---|---|
| IMDb datasets | The trove of troves of entertainment data | TSV | Non-Commercial Licensing | Data is refreshed daily | Current |
| Wikidata | Wikidata is a free and open knowledge base that also contains structured info around movies and tv. | SPARQL | Creative Commons CC0 License | DB is kept up to date with most current movies and TV shows. For example with this query you can pull up all movies release in 2017 | Current |
| The Movie DB API | The Movie Database (TMDb) is a community built movie and TV database. | JSON | Must properly attribute TMDb as the source | DB is kept up to date with most current movies and TV shows | Current |
| OMDB Api | Crowdsourced movie information | JSON | CC BY-NC 4.0 | DB is kept up to date with most current movies | |
| LinkedMDB | open semantic web database for movies, including a large number of interlinks to several datasets | SPARQL | Uncertain | DB seems to entail mostly historical movies | |
| The TV DB | An open database for television fans | XML API | Creative Commons Attribution-NonCommercial 4.0 International License. | Current | |
| Movielens datasets | Movie rating data sets from the MovieLens web site. 26,000,000 ratings and 750,000 tag applications applied to 45,000 movies by 270,000 users | CSV | University of Minnesota retains certain rights. No commercial use without permission | Movielens is kept up to date, but datasets are updated periodically | 8/2017 |
| Cornell – Movie Review Data | Sentiment analysis of movie reviews | TXT | Uncertain | 2004 | |
| UC Irvine – Movie Data Set | A dataset of 10.000 movies with info on actors, casts, directors, producers, studios. | HTML | Copyright held by Gio Wiederhold, 1990-1999. This data may not be used for commercial resale. | Unfriendly format | 1999 |
| WikiPlots | Rather than a dataset, a Phython tool that allows you to create an up to date dataset of movie and book plots from Wikipedia. | Phython | Uncertain but seems open | Better than a dataset | Current |
| Cornell – Movie Dialogs Corpus | a large metadata-rich collection of fictional conversations extracted from 617 raw movie scripts | TXT | Uncertain | 2011 | |
| TMDB 5000 Movie Dataset | Metadata on around 5,000 movies from TMDb | Json | Uncertain | October 2017 | |
| The Movies Dataset | Metadata on over 45,000 movies. 26 million ratings from over 270,000 users derived from different sources. | CSV | Inherits multiple licenses: IMDb, TMDb, Movielens | December 2017 | |
| 32K movies with subtitles and metadata | Useful for linguistical analysis | XLSX | Uncertain | July 2017 | |
| French National Cinema Center datasets | Various datasets related to French cinema including box office data | API/CSV | Open License |
While looking for public data sets I’ve found countless closed services, some of those are worth mentioning here.
Recommendation engines
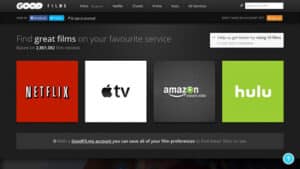
Good Films is a data service and a social network based on a movie recommendation engine. This service aims at facilitating the discovery of movies worth watching by searching the specific subsets of movies available on specific services like Netflix and iTunes.
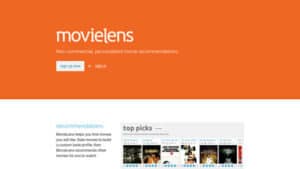
Movielens is a closed source movie recommendation engine based on current data. The aim of the this site is to provide you with movies you will want to watch. The site does not provide links to platforms where you can actually enjoy the newfound movies or buy tickets. The site is a research project run by GroupLens Research at the University of Minnesota.
Box office data

Box Office Mojo is the site where to look up movie performance since the dawn of ages. It’s now part of the Amazon/IMDb family.

The Numbers “Where Data and the Movie Business Meet”; so the site defines itself. It features closed source box office data, a movie star bank-ability index, analysis of the theatrical market but also Home Video data.

JP Box Office Similar to Box Office Mojo, but made in France. This website aggregates a ton of business data around movie releases including both US, China, France, Germany and Italy.
Oddball collections
In the midst of my research I’ve also found data sources that have no immediate business use, but that are nonetheless worth mentioning.
Cornell Movie-Dialogs Corpus is a large metadata-rich collection of fictional conversations extracted from raw movie scripts. Historical and not updated.
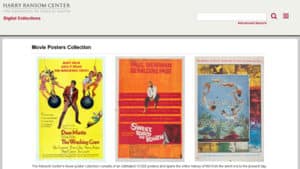
The Harry Ransom Center’s Movie Posters Collection is a fun find and totally free to browse and enjoy on the web.

Scripts from all Seinfeld episodes. That’s an odd and beautiful dataset.
If there’s anything I’ve missed please let me know in the comments. And if you liked what you read here, please subscribe to my almost monthly newsletter where I tackle marketing, productivity, entertainment and innovation.